
Nube de palabras de conferencias presidenciales
Con tantas conferencias presidenciales en México desde hace dos años, ¿te has preguntado qué palabras son las que más se mencionan en ellas? ¿Quiénes han participado y qué han dicho?
Vamos a analizarlo...
En México actualmente se realiza cada día, casi sin falta, una conferencia matutina por parte del Presidente de México, Andrés Manuel López Obrador y algunos miembros del gabinete. Las transcripciones de lo que se dice en dichas conferencias, es publicado en la página del propio gobierno https://presidente.gob.mx/sala-de-prensa/
El profesor Luis Jorge Novelo realizó un interesante análisis con dos discursos presidenciales que también se pueden encontrar en dicho sitio y lo publicó en su perfil de LinkedIn utilizando una wordcloud o nube de palabras.
Una nube de palabras o nube de etiquetas es una representación visual de las palabras que conforman un texto, en donde el tamaño es mayor para las palabras que aparecen con más frecuencia. Wikipedia

Ahora, intentaremos realizar un ejercicio similar pero con las transcripciones de las conferencias diarias comúnmente llamadas "mañaneras" y tratar de separarlo por cada interlocutor.
Pruebas de extracción de información
Iniciaremos el ejercicio con una sola transcripción utilizando herramientas de web scraping, python y Jupyter Notebook.
La conferencia elegida para realizar la primer prueba y análisis será la del 22 de enero del 2021 y se encuentra publicada en ésta dirección.
Empezamos preparando el ambiente e instalando lo necesario; abrimos un Jupyter Notebook y utilizando los paquetes de BeautifulSoup, pandas y numpy, empezamos a obtener el texto.

Se requiere de limpieza de los datos, ya que se puede observar que obtuvimos algunos títulos y leyendas que no necesariamente son parte del discurso o algo dicho por algún interlocutor. También hay partes etiquetadas como inaudibles

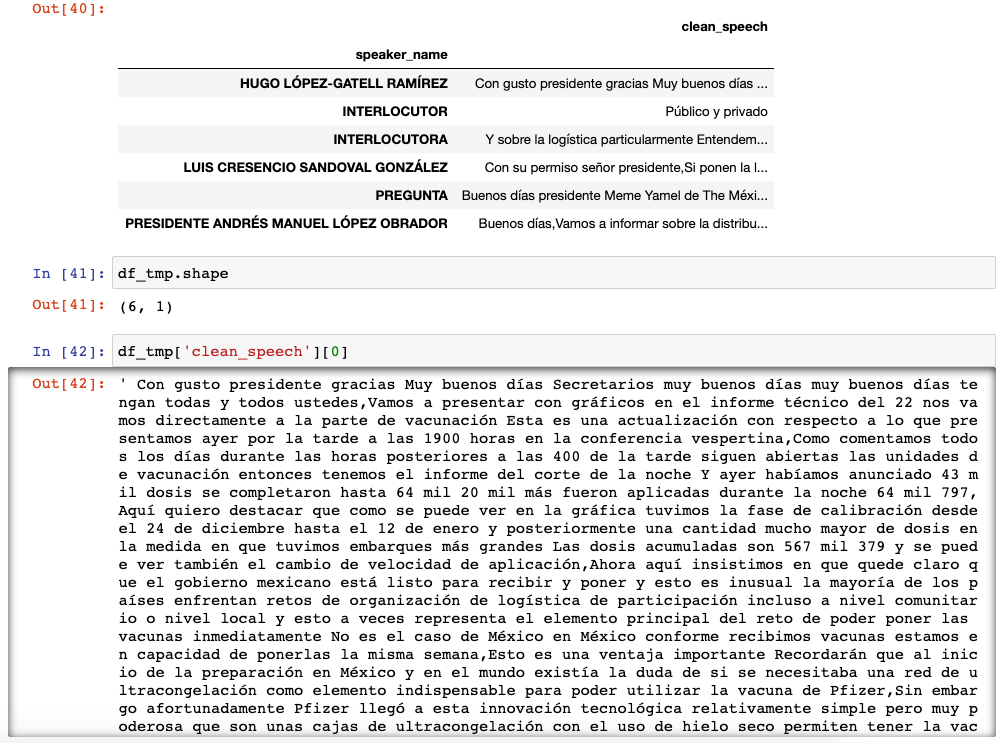
Después de un poco de limpieza y ordenamiento, obtenemos un dataframe con cada párrafo y quien fue el interlocutor de esos párrafos.

Al revisar los distintos interlocutores, encontramos que en ocasiones se les coloca el cargo/puesto, por lo que tenemos que separar los datos.

Después de separar a los distintos interlocutores, sus cargos y asociarlos a sus propios párrafos, obtenemos el siguiente dataframe simplificado en sólo un renglón por interlocutor y discurso.
Generando la nube de palabras
Ahora, vamos a crear la nube de palabras para el presidente.
Primero obtenemos una lista de palabras que vamos a eliminar del conteo como son artículos, conectores, etc. (el, la, los ...) y contamos cada ocurrencia; esto genera la siguiente lista de palabras más utilizadas.

Finalmente utilizando el paquete wordcloud, generamos la nube de palabras final utilizando una imagen de México como máscara.
Las palabras más utilizadas por el presidente en ésta conferencia fueron: vamos, si, entonces, vacunas, vacunación.

Generando otra nube de palabras
De la misma forma generamos la tabla y gráfica para el discurso del Dr. López Gatell.


Consideraciones finales
Ahora podemos darnos una idea de las posibilidades y que podremos generalizar el ejercicio para todas las transcripciones publicadas y obtener análisis adicionales muy interesantes como separar el conteo por interlocutor, por tipo de conferencia, por fecha, etc.
El código de éste ejercicio y sus actualizaciones, lo puedes consultar en GitHub
En próximas publicaciones continuaremos con éste ejercicio y preparando el programa final.
Actualización
Con datos de la conferencia mañanera del 19-feb-2021 *:
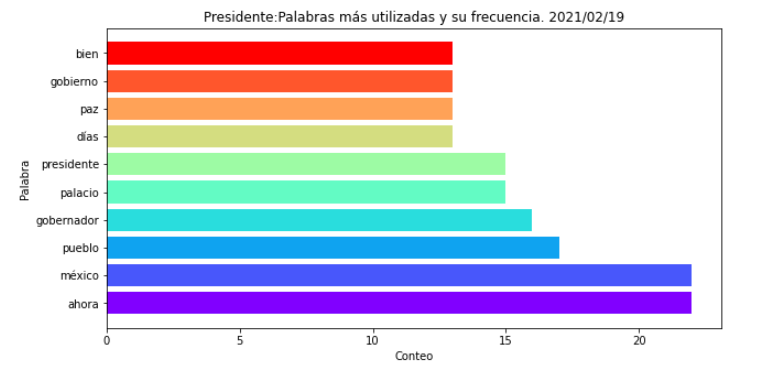
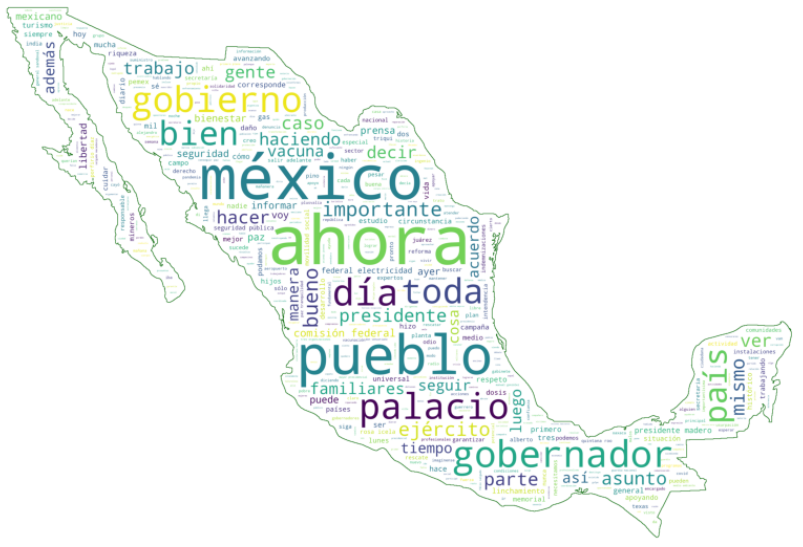
* Sin tomar en cuenta los siguientes conectores/muletillas y sus frecuencias:
entonces: 39
vamos: 32
pues: 28
va: 27
aquí:24
si: 23
Referencias:
- Repositorio en GitHub
- Documentación del paquete wordcloud
- Repositorio del paquete wordcloud en GitHub
- Ejercicio Prof. Luis Jorge Novelo
- Ejemplos de nube de palabras
---
fertorresmx.dev
Twitter: @fertorresmx